Metal-cpp: Performance and Compute
第二册把渲染质量主线搭起来了:mesh、texture、camera、Lambert、Blinn-Phong、PBR。第三册不继续加 GUI,也不继续加基础画质功能,而是把 Metal 当成“可测量、可扩展的 compute 平台”来组织。目标是把同一组输入做成一个稳定的离屏 baseline,然后逐步引入 profiling、frame resources、uniform ring buffer,以及 reduction、prefix sum、blur、particle、tile binning 这些常见 GPU 工作负载。

当前 Book3 的参考代码会实际生成这些输出:
build/MetalCppRenderingEngine/engine-reference.ppmbuild/MetalCppRenderingEngine/engine-blur.ppmbuild/MetalCppRenderingEngine/engine-particles.ppmbuild/MetalCppRenderingEngine/engine-tile-heatmap.ppmbuild/MetalCppRenderingEngine/engine-metrics.txt
Scope
Book2 负责把渲染结果一步一步变好,Book3 负责把同一类程序组织得更稳定、更容易测量,也更容易扩展到更大的 compute 工作负载。这里不会再把重点放在窗口、UI 或更多材质功能上,而是集中处理 buffer、dispatch、同步和 profiling。
Overview
Book3 仍然使用离屏输出,因为这类程序更适合做性能实验:输入固定、输出固定、没有窗口事件和 UI 生命周期干扰。你可以在同一帧里安排多个 compute pass,然后同时检查结果图和 timing。
下面这段是当前阶段要执行的命令,不是写进源码文件的内容。先用它确认 Book3 的 target 已经可以独立构建和运行。
cmake -S . -B build
cmake --build build --target MetalCppRenderingEngine
./build/MetalCppRenderingEngine/MetalCppRenderingEngineProject Layout
第三册的参考代码仍然刻意保持成两个文件:一个 C++ 调度器,一个 Metal shader 文件。这样每一章新增的工作负载都能清楚地落到“CPU 侧怎样组织 buffer 和 command buffer”以及“GPU 侧 kernel 怎样读取这些数据”这两条线上。
下面这段不是要拷贝到某个源码文件里,而是当前 Book3 的目录分工。
main.cpp # pipelines, frame resources, ring buffer, metrics, output files
Shaders.metal # reference render, blur, reduction, prefix sum, particles, tile binningReference Renderer
先保留一个最小 reference renderer。它不是为了追求复杂画面,而是为了给后面的优化和 compute pass 一个稳定基线。当前参考实现仍然使用一个小 quad、一个固定 checker 贴图和一组稳定 camera/light 参数。
打开 main.cpp,先新增 Book3 的基础输入结构和静态场景数据。这一步是新文件初始化,不是修改旧章节里的函数。
struct Vertex
{
Float4 position;
Float4 normal;
Float4 uv;
};
struct Triangle
{
uint32_t a;
uint32_t b;
uint32_t c;
uint32_t _pad;
};
struct Camera
{
Float4 origin;
Float4 lowerLeft;
Float4 horizontal;
Float4 vertical;
Float4 lightDirection;
uint32_t width;
uint32_t height;
uint32_t textureWidth;
uint32_t textureHeight;
uint32_t triangleCount;
uint32_t _pad[3];
};对应的 reference render kernel 写在 Shaders.metal。它会对每个像素发一条射线,和两个三角形做相交,再根据 hit 的 UV 采样 checker 贴图并做最小的 Lambert 漫反射。
kernel void render_mesh(device const Vertex* vertices [[buffer(0)]],
device const Triangle* triangles [[buffer(1)]],
device const uchar4* texturePixels [[buffer(2)]],
constant Camera& camera [[buffer(3)]],
device uchar4* output [[buffer(4)]],
uint2 id [[thread_position_in_grid]])
Profiling First
优化前先测量。第三册先把一帧拆成三个时间段:
- CPU encode time:CPU 创建 encoder、绑定 buffer、安排 dispatch 的时间
- CPU wait time:
waitUntilCompleted()让 CPU 停下来等待 GPU 的时间 - GPU time:Metal 提供的 command buffer GPU 执行时间

在 main.cpp 里新增 timing 记录。下面这段接在 command buffer 编码和提交附近,用来替换“只 commit 不测量”的旧写法。
const auto cpuFrameStart = std::chrono::high_resolution_clock::now();
MTL::CommandBuffer* commandBuffer = queue->commandBuffer();
const auto cpuEncodeEnd = std::chrono::high_resolution_clock::now();
commandBuffer->commit();
const auto cpuWaitStart = std::chrono::high_resolution_clock::now();
commandBuffer->waitUntilCompleted();
const auto cpuFrameEnd = std::chrono::high_resolution_clock::now();
metrics.gpuMs = (commandBuffer->GPUEndTime() - commandBuffer->GPUStartTime()) * 1000.0;运行当前参考实现后,engine-metrics.txt 会写出一组真实数值。当前这份输出里已经能看到“CPU encode 几乎不是问题,主要时间落在等待 GPU 完成”:
cpu_encode_ms: 0.035
cpu_wait_ms: 3.408
cpu_frame_ms: 3.449
gpu_frame_ms: 0.482
gpu_kernel_ms: 2.596
average_luminance: 0.207CPU/GPU Synchronization
第三册开始显式区分“CPU 什么时候可以继续写数据”和“GPU 什么时候已经把上一轮数据读完”。当前参考代码仍然用 waitUntilCompleted() 收尾,因为它最适合教学:你可以稳定读回结果图和 metrics,同时清楚看到等待时间已经被单独测出来了。
在 main.cpp 的帧循环里,先把本帧要写的 shared buffer 清理并填好,再提交 command buffer,最后统一等待。这一段是在已有主循环上继续修改,不是新增独立函数。
FrameResources& frame = frames[frameIndex % kFrameCount];
frame.ringHead = 0;
std::memcpy(frame.prefixInput->contents(), prefixFlags.data(), prefixFlags.size() * sizeof(uint32_t));
std::memcpy(frame.particleA->contents(), particles.data(), particles.size() * sizeof(Particle));
clearBuffer(frame.renderOutput, pixelCount * 4);
clearBuffer(frame.blurOutput, pixelCount * 4);
clearBuffer(frame.partialSums, partialCount * sizeof(float));
commandBuffer->commit();
commandBuffer->waitUntilCompleted();如果以后把 Book3 扩成真正的多帧 in-flight 程序,这一节的思路保持不变,只是把“每帧都等完”改成“只在读回或 ring buffer 即将覆盖时等待”。
Frame Resources
Book2 可以直接在一个 shared buffer 里写完再等 GPU 读完。Book3 要开始显式区分“哪些资源可以长期复用,哪些资源属于某一帧的暂存结果”。

在 main.cpp 里新增 FrameResources。这是新的结构体,可以直接加到辅助结构体定义区域。
struct FrameResources
{
MTL::Buffer* uniformRing = nullptr;
MTL::Buffer* renderOutput = nullptr;
MTL::Buffer* blurOutput = nullptr;
MTL::Buffer* particlePreview = nullptr;
MTL::Buffer* partialSums = nullptr;
MTL::Buffer* prefixInput = nullptr;
MTL::Buffer* prefixOutput = nullptr;
MTL::Buffer* tileCounts = nullptr;
MTL::Buffer* particleA = nullptr;
MTL::Buffer* particleB = nullptr;
uint32_t ringHead = 0;
};然后在主循环里按 frame index 轮换它们。这里虽然最终还是离屏程序,仍然可以先把资源组织成真实渲染循环会使用的形状。
std::array<FrameResources, kFrameCount> frames{};
for (uint32_t frameIndex = 0; frameIndex < kFrameCount; ++frameIndex)
{
FrameResources& frame = frames[frameIndex % kFrameCount];
frame.ringHead = 0;
clearBuffer(frame.renderOutput, pixelCount * 4);
clearBuffer(frame.blurOutput, pixelCount * 4);
clearBuffer(frame.tileCounts, tileCount * sizeof(uint32_t));
}Uniform Ring Buffer
第三册的程序一帧里会安排多个不同的 compute pass:render、blur、reduction、prefix sum、particle、tile binning。不要为每个 pass 创建一个新的小 buffer。更稳妥的做法是一个大 shared buffer,里面按 256 字节对齐切片,每个 pass 绑定不同 offset。
先在 main.cpp 中新增 ring allocator。这是新的辅助函数,可以放在资源创建函数附近。
RingSlice allocateRing(FrameResources& frame, uint32_t bytes)
{
const uint32_t alignedBytes = align256(bytes);
RingSlice slice;
slice.offset = frame.ringHead;
slice.cpuPointer = static_cast<uint8_t*>(frame.uniformRing->contents()) + frame.ringHead;
frame.ringHead += alignedBytes;
return slice;
}接着把各个 pass 的参数写到不同 slice,再把同一个 uniformRing 用不同 offset 绑定给 encoder。
const RingSlice cameraSlice = allocateRing(frame, sizeof(Camera));
std::memcpy(cameraSlice.cpuPointer, &camera, sizeof(Camera));
const RingSlice imageSlice = allocateRing(frame, sizeof(ImageParams));
std::memcpy(imageSlice.cpuPointer, &imageParams, sizeof(ImageParams));
encoder->setBuffer(frame.uniformRing, cameraSlice.offset, 3);
encoder->setBuffer(frame.uniformRing, imageSlice.offset, 2);Data Layout
第三册第一次需要认真看数据布局。当前粒子系统采用 AoS,也就是每个粒子把 position 和 velocity 放在一起。因为这一册的 particle_step 每次都会同时读取和写回这两个字段,这种布局更直观,也更适合新手先把 ping-pong 更新跑通。
在 main.cpp 和 Shaders.metal 里都先保持同一个 Particle 结构。这是新结构定义,不是在旧函数中补几行。
struct Particle
{
Float2 position;
Float2 velocity;
};等你把这一版跑通后,可以再尝试把它拆成 SoA,例如单独的 positionX[]、positionY[]、velocityX[]、velocityY[]。教程当前版本先不强行切到 SoA,因为 Book3 的重点是让你看到“布局影响后续优化空间”,而不是一次引入两套粒子实现。
Pipeline and Resource Cache
Book3 不应该在每一帧里重复创建 pipeline。当前参考代码把所有 compute pipeline 在启动阶段统一创建好,然后整帧复用。这就是本书里的最小 pipeline cache。
在 main.cpp 中新增 Pipelines 结构和辅助函数。这是新的启动期代码,可以直接加到资源创建辅助函数附近。
struct Pipelines
{
MTL::ComputePipelineState* render = nullptr;
MTL::ComputePipelineState* blur = nullptr;
MTL::ComputePipelineState* reduction = nullptr;
MTL::ComputePipelineState* prefix = nullptr;
MTL::ComputePipelineState* particleStep = nullptr;
MTL::ComputePipelineState* particleRaster = nullptr;
MTL::ComputePipelineState* tile = nullptr;
};Pipelines pipelines = makePipelines(device, library);
if (!pipelinesReady(pipelines))
{
releasePipelines(pipelines);
return 1;
}教程这里先把“cache”理解为“创建一次,重复使用”。如果以后继续扩展 Book3,再把 texture、sampler、argument buffer 的缓存策略放进同一套路里。
Threadgroup Shape
不同 kernel 不该盲目共用同一个 threadgroup 形状。二维图像 pass 更适合二维 tile;粒子更新和 tile binning 更适合一维批次;reduction 需要让 threadgroup 大小和共享 scratch 数组匹配。
在 main.cpp 中,把硬编码的 threadgroup 尺寸提成常量和小辅助函数。下面这段是在已有常量区和辅助函数区继续补充。
constexpr uint32_t kThreadgroup1D = 256;
constexpr uint32_t kImageThreadsX = 16;
constexpr uint32_t kImageThreadsY = 8;
constexpr uint32_t kParticleThreads = 64;
MTL::Size makeImageThreadgroup()
{
return MTL::Size::Make(kImageThreadsX, kImageThreadsY, 1);
}
MTL::Size makeLinearThreadgroup(uint32_t width)
{
return MTL::Size::Make(width, 1, 1);
}然后把 dispatch 调用改成带语义的 helper,而不是到处写裸数字:
encoder->dispatchThreads(MTL::Size::Make(kWidth, kHeight, 1),
makeImageThreadgroup());
encoder->dispatchThreads(MTL::Size::Make(kParticleCount, 1, 1),
makeLinearThreadgroup(kParticleThreads));Command Encoding Strategy
Book3 的 command buffer 不再只装一个 kernel。当前参考实现一帧里会依次编码这些工作:
1. render_mesh
2. reduce_luminance
3. blur_image
4. prefix_sum_16
5. particle_step (ping-pong for 24 steps)
6. rasterize_particles
7. tile_bin_particles这套顺序的目标不是“最强性能”,而是把不同类型的 compute workload 都塞进同一个 command buffer,让你能同时看 timing、结果图和指标文件。
Parallel Reduction
Reduction 是第三册第一个真正的“性能型 compute kernel”。它把整张 reference image 的亮度压缩成一组 partial sums,再由 CPU 把这些 partial sums 做最终求和。这样可以先理解 threadgroup 内归约,再考虑更复杂的纯 GPU 多阶段归约。
在 Shaders.metal 中新增 reduce_luminance。这是新 kernel,不替换 render_mesh。
threadgroup float scratch[256];
float value = 0.0;
if (gid < params.pixelCount)
{
const uchar4 pixel = input[gid];
const float3 rgb = float3(pixel.r, pixel.g, pixel.b) / 255.0;
value = dot(rgb, float3(0.2126, 0.7152, 0.0722));
}
scratch[tid] = value;
threadgroup_barrier(mem_flags::mem_threadgroup);
for (uint stride = 128; stride > 0; stride >>= 1)
{
if (tid < stride)
{
scratch[tid] += scratch[tid + stride];
}
threadgroup_barrier(mem_flags::mem_threadgroup);
}CPU 侧最终只需要把 partial sums 再加一次,就能得到平均亮度:
const float* partialSums = static_cast<const float*>(frame.partialSums->contents());
double luminanceSum = 0.0;
for (uint32_t i = 0; i < partialCount; ++i)
{
luminanceSum += partialSums[i];
}
metrics.averageLuminance = luminanceSum / static_cast<double>(pixelCount);Prefix Sum
Prefix sum 比 reduction 多一步:它不是把所有数据压成一个值,而是把“前面有多少个有效元素”写成每个位置自己的 offset。Book3 先用一个 16 元素的小例子把算法轮廓跑通。

在 Shaders.metal 中新增 prefix_sum_16。它使用 threadgroup scratch 数组做一版简单的 Hillis-Steele scan。
threadgroup uint scratch[16];
scratch[tid] = input[tid];
threadgroup_barrier(mem_flags::mem_threadgroup);
for (uint offset = 1; offset < params.count; offset <<= 1)
{
uint value = scratch[tid];
if (tid >= offset)
{
value += scratch[tid - offset];
}
threadgroup_barrier(mem_flags::mem_threadgroup);
scratch[tid] = value;
threadgroup_barrier(mem_flags::mem_threadgroup);
}
output[tid] = (tid == 0) ? 0 : scratch[tid - 1];当前参考程序会把一个固定 flag 数组和它对应的 prefix output 写进 engine-metrics.txt,便于核对算法是否正确:
prefix_input: 1 0 1 1 0 1 0 1 1 0 0 1 1 1 0 1
prefix_output: 0 1 1 2 3 3 4 4 5 6 6 6 7 8 9 9Image Convolution
第一册已经做过 blur。第三册把它放回性能路线里,目的不是重新教一次卷积,而是让 blur 成为一个“第二个稳定工作负载”:它会读取邻域,会大量访问 image buffer,也很适合以后继续尝试 threadgroup memory 优化。
在 Shaders.metal 中新增 blur_image。这是新 kernel,不替换第一册的实现。
const int weights[3][3] = {
{1, 2, 1},
{2, 4, 2},
{1, 2, 1},
};
for (int offsetY = -1; offsetY <= 1; ++offsetY)
{
for (int offsetX = -1; offsetX <= 1; ++offsetX)
{
const uint sampleX = uint(clamp(int(id.x) + offsetX, 0, int(params.width) - 1));
const uint sampleY = uint(clamp(int(id.y) + offsetY, 0, int(params.height) - 1));
const uchar4 sample = source[sampleY * params.width + sampleX];
accum += float3(sample.r, sample.g, sample.b) * weight;
}
}
Particle Simulation
粒子系统是第三册里“compute 更新 -> compute 可视化”的例子。当前参考实现没有再引入 render pipeline,而是继续坚持纯 compute:先更新粒子位置,再用另一个 kernel 直接把粒子画进离屏 image buffer。
先在 Shaders.metal 中新增 particle_step。它读取当前粒子数组,写到下一块粒子数组,实现最小的 ping-pong 更新。
kernel void particle_step(device const Particle* currentParticles [[buffer(0)]],
device Particle* nextParticles [[buffer(1)]],
constant ParticleParams& params [[buffer(2)]],
uint id [[thread_position_in_grid]])
{
Particle particle = currentParticles[id];
particle.position += particle.velocity * params.dt;
if (particle.position.x < 0.05 || particle.position.x > 0.95)
{
particle.velocity.x *= -1.0;
}
if (particle.position.y < 0.08 || particle.position.y > 0.92)
{
particle.velocity.y *= -1.0;
}
nextParticles[id] = particle;
}然后再新增 rasterize_particles,把粒子数组转成一张可见图像。当前实现让每个像素遍历所有粒子并叠加 glow,重点是结果稳定,便于后续观察 tile binning 的作用。

Tile-Based Culling
Tile culling 的核心思想是“先把对象分配到小块里,再让后续阶段只看自己那一小块”。第三册先不做完整的 tile lighting,而是用粒子示例做一个可运行的 tile binning:每个粒子根据自己落在哪个 tile,给那个 tile 的计数器做一次原子加一。

在 Shaders.metal 中新增 tile_bin_particles:
const uint pixelX = min(uint(position.x * params.width), params.width - 1);
const uint pixelY = min(uint(position.y * params.height), params.height - 1);
const uint tileX = min(pixelX / params.tileSize, params.tilesX - 1);
const uint tileY = min(pixelY / params.tileSize, params.tilesY - 1);
const uint tileIndex = tileY * params.tilesX + tileX;
atomic_fetch_add_explicit(&tileCounts[tileIndex], 1u, memory_order_relaxed);CPU 侧再把这个 tileCounts buffer 转成热力图,方便快速看分布是否正确:
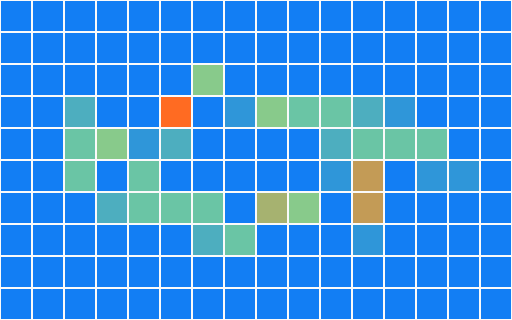
Verification
第三册的验证不再只有“有没有一张图”。当前参考实现每次运行后都应该同时给出:
engine-reference.ppm:reference render 是否稳定engine-blur.ppm:blur kernel 是否正常engine-particles.ppm:particle ping-pong 是否正常engine-tile-heatmap.ppm:tile binning 是否正常engine-metrics.txt:profiling、average luminance、prefix output、tile counts
如果你继续优化 threadgroup size、buffer layout 或 kernel 数量,先固定这批输出,再逐步比较 timing 变化。
GPU Capture and Debug
Book3 的结果图和 metrics 只能告诉你“结果是否变化”和“一帧大概花了多久”。如果要看每个 encoder、每个 dispatch 和每个 buffer 绑定,就需要 Xcode GPU Capture。
当前参考程序是命令行 target,可以直接从 Xcode 或 Instruments 启动它。调试时先关注三件事:
render_mesh、blur_image、reduce_luminance、prefix_sum_16、particle_step、rasterize_particles、tile_bin_particles是否按书中顺序出现在同一个 command buffer 里。- 每个 pass 绑定的 buffer index 是否和
Shaders.metal里的[[buffer(n)]]一致。 - threadgroup size 是否符合本章设置:图像 pass 使用二维 threadgroup,粒子和 tile pass 使用一维 threadgroup,reduction 使用 256 个 thread。
如果某张结果图是黑的,先看 GPU Capture 里的 resource binding;如果 metrics 明显变慢,先看 command buffer 中哪个 dispatch 占用时间变长。这样调试顺序和本书的教学顺序保持一致。
CMake Changes
第三册的 target 仍然保持纯 C++,不新增 GUI 依赖。当前 `CMakeLists.txt` 里 Book3 的最小 target 定义如下:
add_executable(MetalCppRenderingEngine
src/MetalCppRenderingEngine/main.cpp)由于 shader 仍然走单独编译,Book3 的 `.metal -> .air -> .metallib` 规则保持和前两册一致:
set(BOOK3_DIR "${CMAKE_BINARY_DIR}/MetalCppRenderingEngine")
set(BOOK3_METALLIB "${BOOK3_DIR}/default.metallib")
add_custom_command(
OUTPUT "${BOOK3_METALLIB}"
COMMAND xcrun -sdk macosx metal
"-fmodules-cache-path=${BOOK3_DIR}/ModuleCache"
-c "${CMAKE_CURRENT_SOURCE_DIR}/src/MetalCppRenderingEngine/Shaders.metal"
-o "${BOOK3_DIR}/Shaders.air"
COMMAND xcrun -sdk macosx metallib
"${BOOK3_DIR}/Shaders.air"
-o "${BOOK3_METALLIB}"
DEPENDS src/MetalCppRenderingEngine/Shaders.metal)Reference Code
最终参考代码目录是 src/MetalCppRenderingEngine/。如果你想核对当前 Book3 的最终版本,可以对照下面的文件清单:
下面同样是目录清单,不是要粘贴进源码的代码块。
src/MetalCppRenderingEngine/
main.cpp
Shaders.metal
build/MetalCppRenderingEngine/
engine-reference.ppm
engine-blur.ppm
engine-particles.ppm
engine-tile-heatmap.ppm
engine-metrics.txtmain.cpp:对应 `Reference Renderer`、`Profiling First`、`CPU/GPU Synchronization`、`Frame Resources`、`Uniform Ring Buffer`、`Data Layout`、`Pipeline and Resource Cache`、`Threadgroup Shape`、`Verification`,负责 pipeline、dispatch、metrics 和输出文件。Shaders.metal:对应 `Reference Renderer`、`Parallel Reduction`、`Prefix Sum`、`Image Convolution`、`Particle Simulation`、`Tile-Based Culling`,包含所有 Book3 的 compute kernel。
最后这段仍然是运行命令,用来验证你已经完成了整本书的当前版本。
cmake -S . -B build
cmake --build build --target MetalCppRenderingEngine
./build/MetalCppRenderingEngine/MetalCppRenderingEngine