I am currently a joint master’s student at SIGS of Tsinghua University and Huawei Technologies, supervised by Prof. Ran Liao and Dr. Duan Gao. My research focuses on the intersection of computer vision, computer graphics, and deep learning, with a focus on 3D/2D generation. I’m also involved in denoising for Monte Carlo rendering and model watermarking during my internship. Before that, I received my B.E. degree in 2022 from Shanghai Polytechnic University.
🔥 News
- 2024.10: I’m looking for an opportunity to study for a Ph.D.
📝 Selected Publications
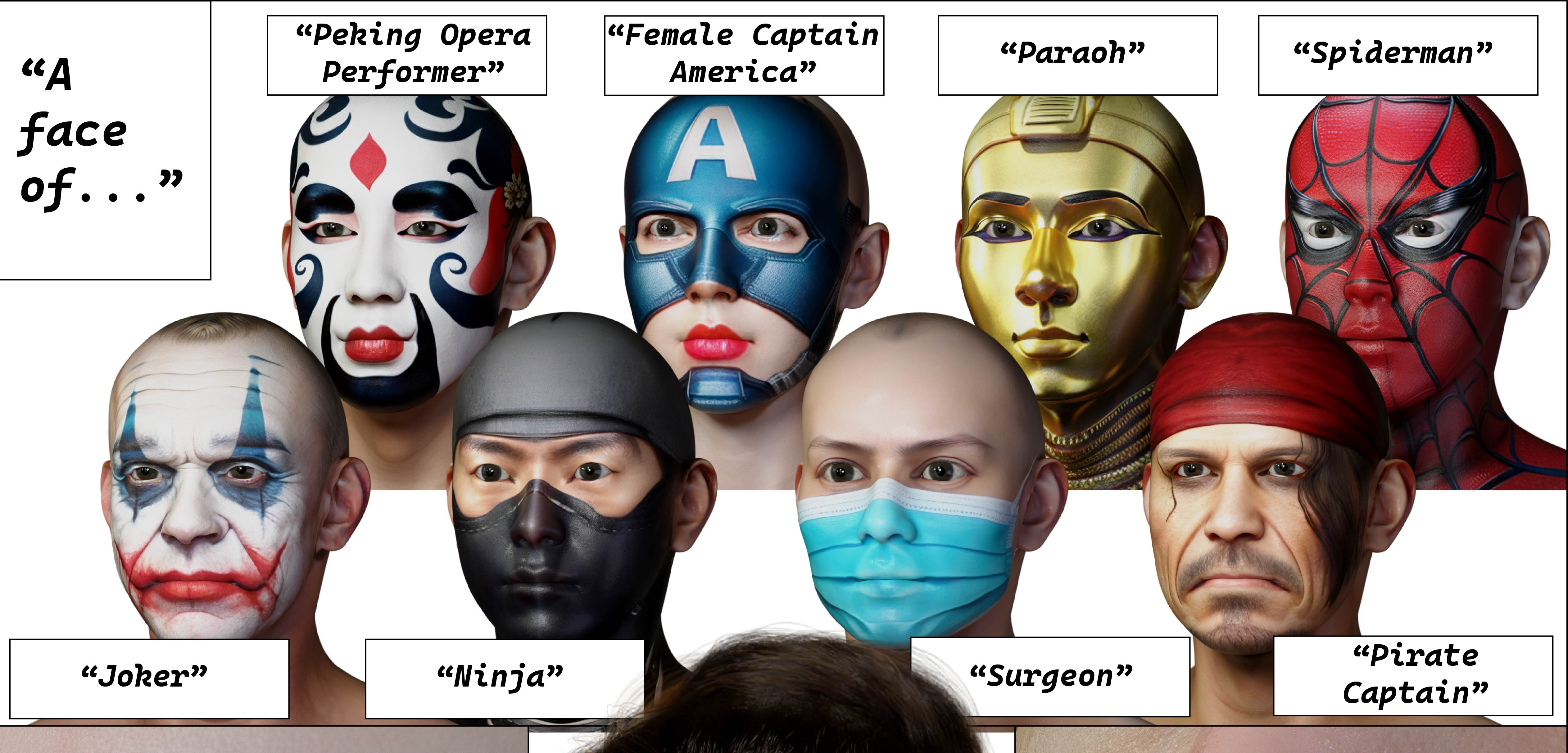
Jinfu Wei*, Zheng Zhang*, Ran Liao, Duan Gao
- A novel framework for generating high-quality digital faces, combining the diversity inherent in pre-trained T2I diffusion models with the 3D facial priors;
- A controllable diffusion model that can generate 4K PBR facial maps supporting few-shot training and fast generation in a feed-forward manner;
- A wide range of manipulations and controls, allowing for both localized and global editing and precise adjustments to facial geometry at both detailed (wrinkles) and overall levels (topology).

UniFaceGAN: High-Quality 3D face Editing with a Unified Latent Space
Jinfu Wei, Zheng Zhang, Ran Liao, Duan Gao
- A 3D face generation framework, which bridges a unified latent space for geometry and PBR materials of faces, enabling high-quality 3D face generation and editing;
- A stylization method to synchronously manipulate PBR appearances with only a simple text description;
- A novel way to manipulate face geometries with prior of GANs, which preserves better facial consistency than previous methods.

DreamPBR: Text-driven Generation of High-resolution SVBRDF with Multi-modal Guidance
Linxuan Xin, Zheng Zhang, Zhiyi Pan, Jinfu Wei, Wei Gao, Duan Gao
- We introduce a novel generative framework for high-quality material generation under text and multi-modal guidances that combine pre-trained 2D diffusion model and material domain priors efficiently;
- We present a rendering-aware decoder module that learns the mapping from a shared latent space to SVBRDFs;
- Our multi-model guidance module offers rich user-friendly controllability, enabling users to manipulate the generation process effectively;
- We propose an image-to-image editing scheme that facilitates material editing tasks such as stylization, inpainting, and seamless texture synthesis.
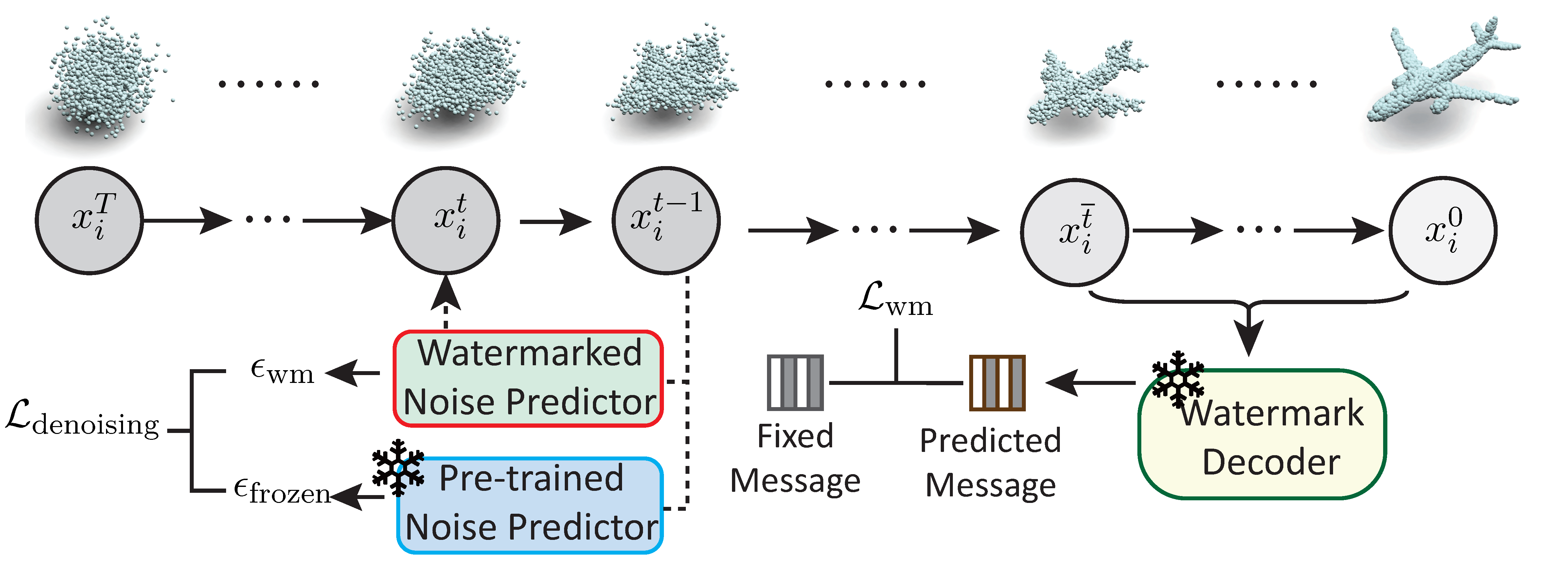
Dual-Process Watermarked Diffusion: Integrating Watermarking with Denoising in Point Clouds
Jinfu Wei*, Heng Chang*, Xiaohang Liu*, Li Liu, Likun Li, Shiji Zhou, Chengyuan Li, Di Xu, Wei Gao, Ran Liao
- The first approach to add watermarks in DMs for point cloud generation;
- PI-HiDDeN tackles the challenge of extracting watermarks in the point cloud from the permutation invariant embedding space.
- The dual-period distilling confronts the challenge of the accumulation of gradients in DMs that prevents the completion of the point cloud;
ICASSP2025 Implanting Robust Watermarks in Latent Diffusion Models for Video Generation Xiaohang Liu*, Heng Chang*, Jinfu Wei, Lei Zhu, Li Liu, Likun Li, Shiji Zhou, Chengyuan Li, Di Xu, Wei Gao
💻 Internships
- 2023.05 - 2024.12, Media Innovation Lab, Huawei, China.
💡 Misc
- I am a big fan of detective fiction novels and movies.
- I tend to jog if too tired after a day’s study.
- I like games with a high degree of freedom and/or excellent plots. (The Legend of Zelda, The Witcher, Elden Ring, Wukong…)